50. Последовательный канал. Асинхронный режим
передачи данных.
При асинхронном режиме
передаваемые биты информации разделяются специальными битами.
Три режима работы:
1ый режим – стандартный 8ми
битовый асинхронный режим
Использование: организация
обычных каналов последовательной связи между контролером и компьютером.
Структура 10-битового фрейма данных:

В этом режиме посылка данных
представляет собой 10- битовый фрейм,
состоящий из стартового бита, 8 бит данных , передаваемых, начиная с младшего
бита и стопового бита.Если разрешен контроль на четность, то вместо 8-го бита
предается бит четности и производиться автоматическая проверка четности при
приеме данных. В этом случае общее количество передаваемых битов (Единиц)
дополняется до четного числа. Например, при передачи 0100000 в качестве бита
контроля четности (8-й бит ) будет передана 1.
Способы контроля четности в
передатчике и приемнике должны быть одинаковы. Приемник получив данные вместе с
контрольным битом, автоматически проверяет их правильность и в случае ошибки
генерируется запрос прерывания ошибки обмена.
2-й режим – отличается от
1-го дополнительным битом передаваемым по каналу связи.
11-битовый фрейм данных:

Перед передачей каждого байта
данных в этом режиме МП на стороне передатчика устанавливает значение 9-го бита
в регистре управления, а уже затем идет передача непосредственно данных. После
передачи данных 9-й бит аппаратно очищается, т.е обнуляется.
В этом режиме проверку
четности задавать нельзя, т.к будет вызвана ошибка приема данных на стороне
приемника.
3-й режим- этот режим
отличается от 2-го , тем что допускает контроль четности.
Если контроль четности
разрешен, то 9-й бит фрейма данных формируется передатчиком автоматически в виде контрольного разряда.
51. Последовательность обработки команд
микропроцессором.
Функционирование МП систем состоит в передачах слов между регистрами. Порядок передач, часть из которых сопровождается преобразованием слов, определяется последовательностью команд программы.

Функционирование МП систем состоит в передачах слов между регистрами. Порядок передач, часть из которых сопровождается преобразованием слов, определяется последовательностью команд программы.
Команды
дешифруются устройствами управления и преобразуются в определенные
последовательности управляющих сигналов.
Команды
состоят из 2-х полей:
1.
поле операции
(оператор), которое определяет выполняемые действия или операцию.
2.
поле операнда –
это данные участвующие в операции.
Длина
первого поля обычно составляет 1 байт и называется кодом операции (КОП).
В
современных МП используется адресный принцип построения команд, т.е. когда в
поле операнда содержатся не значение операнда, хотя такое допускается, а адрес
регистра, содержащего операнд и называемого регистром источника.
При
выполнении команд МП выполняет следующие действия:
1.
выборка очередной
команды из памяти ЭВМ
2.
декодирование
очередной команды
3.
чтение операндов
из памяти ЭВМ (если это требуется команде)
4.
выполнение
команды
5.
запись
результатов в память, если это требуется командой.
В современных МП эти операции
разделены между отдельными устройствами.
ОУ – осуществляет
непосредственное выполнение машинной команды.
ШИ – выборка команд, чтение
операндов и если необходимо запись результатов.
Указанные устройства могут
функционировать независимо друг от друга поэтому в большинстве случаев возможно
одновременное выборка следующей команды и выполнение текущей.
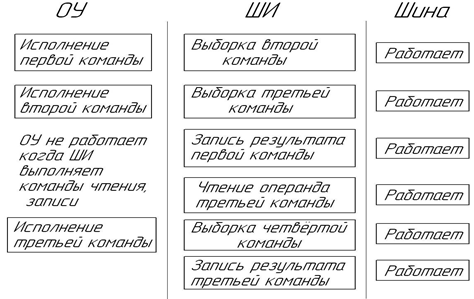
ШИ
– обеспечивает доступ ко всей памяти. В МП имеется внутренняя память, которая
называется очередью команд, которая может хранить от 4 и более байтов
соответствующих потоку выбранных команд. Очередь работает по принципу FIFO (First
input, first
output), т.е. на выходе сохраняется порядок поступления
команд. Если один байт в очереди команд свободен и не активирован, запрос от
ОУ, ШИ автоматически осуществляет выборку следующего байта команды. При
нарушении последовательности исполнения команд, выполнение команды передачи
управления (CALL, JMP), ШИ “сбрасывает” очередь команд и осуществляет
выборку команды по новому адресу, предаёт её в ОУ, а затем начинает заполнение
очереди из следующих ячеек. ШИ приостанавливает выборку команд когда ОУ
запрашивает операции считывания / записи в память или в порт.
52. Источники прерываний. Последовательность
обработки прерываний. Приоритеты прерываний, поступающих в микропроцессор.
Современные
МП имеют универсальную систему прерываний. Каждому прерыванию поставлены
составление код типа прерывания, который определяет вид прерываний для МП.
Допускается до 256 типов прерываний.
Прерывания
могут инициироваться устройствами внешними по отношению к МП, а также командами
программных прерываний.
Кроме
того, в некоторых ситуациях прерывания генерирует сам МП.
Прерывания
следует рассмотреть как некоторый сигнал заставляющий МП прерывать выполнение
текущей программы и переключатся на выполнение др. более важной или срочной
программы, называемой программой обслуживания прерывания.
После
обслуживания прерывания возобновляется выполнение прерванной программы. Для
успешной правильной реакции МП на прерывание прерванная программа
возобновляется как будто прерывания вообще не было.
Внешние
прерывания могут появляться в
произвольный момент времени, т.е. асинхронно по отношению к действиям МП.
Перед
выполнением процедуры обслуживания прерывания МП должен запомнить место в
прерванной программе, где возникло прерывание, для этого МП сохраняет в стеке,
помимо регистра флагов, адрес возврата, который хранится в регистрах CS и IP. Регистр
флагов сохраняется в стеке для того чтобы запомнить все статусные и управляющие
флажки, определяющие работу МП.
После
выполнения программы обслуживания прерывания МП извлекает из стека в регистры CS и IP адрес
возврата и в регистр флагов флажки и переходит к выполнению следующей команды
программы.
53. Системные платы современных ПЭВМ. Построение и сравнительный анализ.
Унификация распространяется не только на компоненты ЭВМ, но и на системные платы хотя в настоящее время встречается исключения когда фирменные системные платы устанавливаются в «родные» корпуса так как имеют специальные габаритные и присоединительные размеры.
IBM PC/2
ACEP
Compaq
Digital
Packard Bell
В настоящее время применяется
следующие унифицированные системные платы:
- Класса АТ
- Класса АТХ
1-й тип применяется для
системных корпусов:
DeskTop, Mini, Midi , Big Towen.
Данная системная плата имеет
фиксированное расположение слотов и разъема клавиатуры относительно задней
кромки платы.
АТХ
Новый стандарт АТХ
существенно упрощает соединения, задавая удобное местоположение ключевых
компонентов системной платы.
Основные новшества компановки
АТХ:
- Все внешние разъемы
(клавиатуры и встроенной периферии) сгруппированы у одного края системной
платы, для них предназначено одно большое прямоугольное окно в корпусе
системного блока.
- Микропроцессор
располагается под блоком питания и его радиатор обдувается потоком воздуха
внутреннего вентилятора блока питания. Расстояние между блоком питания и
микропроцессором по высоте позволяет менять последний без снятия системной
платы.
- Разъемы адаптеров FDD и IDE расположены
ближе к одному краю системной платы, что позволяет более рационально разместить
кабели в корпусе с сокращением их длины.
- Модули памяти
устанавливаются в легкодоступном месте.
- Для блока питания определен
сигнал программно управляющего отключения питания, что является эффективной
защитой от преждевременного выключение питания при незакрытых программных
приложениях.
- Блок питания имеет дежурный
маломощный источник питания 5 V для питания
цепей управления и устройств активных в «спящем» режиме. (Питание факс-модема
способного по звонку «разбудить» ЭВМ.
На системных платах данного
класса чипсет определяет тип поддерживаемой памяти, виды шин, микропроцессора и
различных интегральных устройств:
Графического контроля, USB портов, сетевой адаптер.
Выбор чипсетов сегодня
достаточно разнообразен:
1)
AMD
2)
INTEL
3)
VIA
4)
SIS
5)
nvIDIA
6)
ATi
Современный чипсет состоит из
2-х микросхем называемые северным и южным мостами. Северный мост легко
распознать на системной плате он всегда закрыт радиатором. Распологается вблизи
микропроцессора.
Такое расположение связано с
тем, что северный мост работает интенсивней, вследствие чего нагревается
быстрее.
Функции северного моста
чипсета:
1)
Взаимодействие с
оперативной памятью
2)
Взаимодействие с
ЦП (системная шина)
3)
Взаимодействие с
графической подсистемой (шина AGP)
4)
Взаимодействие с
южным мостом чипсета
Южный мост чипсета соединен с
такими компонентами: HDD, USB и другими устройствами, более медленные чем выше
рассмотренные.
В настоящее время применяются
следующие чипсеты:
INTEL 850Е для высоко
производительных рабочих станций потдерживающих работу 533 МГц системной шины и
имеющих 6 портов USB.
54. Параллельный интерфейс микропроцессорных
систем.
Порт параллельного интерфейса был введен в PC для подключения принтера. Отсюда и пошло его название — LPT (Line Printer Terminal — порт построчного принтера). Традиционный, он же стандартный, LPT-порт (называемый еще SPP-портом) ориентирован на вывод данных, хотя с некоторыми ограничениями позволяет и вводить данные. Существуют различные модификации LPT- порта — двунаправленный, EPP, ECP и др., расширяющие его функциональные возможности, повышающие производительность и снижающие нагрузку на процессор. Поначалу они являлись фирменными решениями отдельных производителей, позднее был принят стандарт IEEE 1284.
С внешней стороны порт имеет 8-битную шину данных, 5-битную шину сигналов состояния и 4-битную шину управляющих сигналов, выведенные на разъем-розетку DB-25S. В LPT-порте используются логические уровни ТТЛ, что ограничивает допустимую длину кабеля из-за невысокой помехозащищенности ТТЛ-интерфейса. Гальваническая развязка отсутствует — схемная «земля» подключаемого устройства соединяется со схемной «землей» компьютера. Из-за этого порт является уязвимым местом компьютера, страдающим при нарушении правил подключения и заземления устройств. Поскольку порт обычно располагается на системной плате, в случае «выжигания» порта зачастую выходит из строя и его ближайшее окружение, вплоть до выгорания всей системной платы.
С программной стороны LPT-порт представляет собой набор регистров, расположенных в адресном пространстве ввода-вывода. Регистры порта адресуются относительно базового адреса порта, стандартными значениями которого являются 3BCh, 378h и 278h. Порт может использовать линию запроса аппаратного прерывания, обычно IRQ7 или IRQ5. В расширенных режимах может использоваться и канал DMA.
Практически все современные системные платы (еще начиная с PCI-плат для процессоров 486) имеют встроенный адаптер LPT-порта. На старых картах ISA LPT-порт чаще всего соседствует с парой СОМ-портов, а также с контроллерами дисковых интерфейсов (FDC и IDE). Кроме того, LPT-порт обычно присутствует на плате старинного дисплейного адаптера MDA (монохромный текстовый) и HGC (монохромный графический «Геркулес»). Есть и карты PCI с дополнительными LPT-портами.
55. Использование масок IP-адреса.
Порт параллельного интерфейса был введен в PC для подключения принтера. Отсюда и пошло его название — LPT (Line Printer Terminal — порт построчного принтера). Традиционный, он же стандартный, LPT-порт (называемый еще SPP-портом) ориентирован на вывод данных, хотя с некоторыми ограничениями позволяет и вводить данные. Существуют различные модификации LPT- порта — двунаправленный, EPP, ECP и др., расширяющие его функциональные возможности, повышающие производительность и снижающие нагрузку на процессор. Поначалу они являлись фирменными решениями отдельных производителей, позднее был принят стандарт IEEE 1284.
С внешней стороны порт имеет 8-битную шину данных, 5-битную шину сигналов состояния и 4-битную шину управляющих сигналов, выведенные на разъем-розетку DB-25S. В LPT-порте используются логические уровни ТТЛ, что ограничивает допустимую длину кабеля из-за невысокой помехозащищенности ТТЛ-интерфейса. Гальваническая развязка отсутствует — схемная «земля» подключаемого устройства соединяется со схемной «землей» компьютера. Из-за этого порт является уязвимым местом компьютера, страдающим при нарушении правил подключения и заземления устройств. Поскольку порт обычно располагается на системной плате, в случае «выжигания» порта зачастую выходит из строя и его ближайшее окружение, вплоть до выгорания всей системной платы.
С программной стороны LPT-порт представляет собой набор регистров, расположенных в адресном пространстве ввода-вывода. Регистры порта адресуются относительно базового адреса порта, стандартными значениями которого являются 3BCh, 378h и 278h. Порт может использовать линию запроса аппаратного прерывания, обычно IRQ7 или IRQ5. В расширенных режимах может использоваться и канал DMA.
Практически все современные системные платы (еще начиная с PCI-плат для процессоров 486) имеют встроенный адаптер LPT-порта. На старых картах ISA LPT-порт чаще всего соседствует с парой СОМ-портов, а также с контроллерами дисковых интерфейсов (FDC и IDE). Кроме того, LPT-порт обычно присутствует на плате старинного дисплейного адаптера MDA (монохромный текстовый) и HGC (монохромный графический «Геркулес»). Есть и карты PCI с дополнительными LPT-портами.
IP-адрес –
это уникальный числовой адрес, однозначно идентифицирующий узел, группу узлов
или сеть. IP-адрес имеет длину 4 байта и обычно записывается в виде четырех
чисел (так называемых «октетов»), разделенных точками – W.X.Y.Z , каждое
из которых может принимать значения в диапазоне от 0 до 255, например,
213.128.193.154.
Схема
разделения IP-адреса на номер сети и номер узла, основанная на понятии класса
адреса, является достаточно грубой, поскольку предполагает всего 3 варианта
(классы A, B и C) распределения разрядов адреса под соответствующие номера.
Рассмотрим для примера следующую ситуацию. Допустим, что некоторая компания,
подключающаяся к Интернет, располагает всего 10-ю компьютерами. Поскольку
минимальными по возможному числу узлов являются сети класса C, то эта компания
должна была бы получить от организации, занимающейся распределением IP-адресов,
диапазон в 254 адреса (одну сеть класса C). Неудобство такого подхода очевидно:
244 адреса останутся неиспользованными, поскольку не могут быть распределены
компьютерам других организаций, расположенных в других физических сетях. В
случае же, если рассматриваемая организация имела бы 20 компьютеров,
распределенных по двум физическим сетям, то ей должен был бы выделяться
диапазон двух сетей класса C (по одному для каждой физической сети). При этом
число "мертвых" адресов удвоится.
Для более гибкого определения границ между разрядами номеров сети и узла внутри IP-адреса используются так называемые маски подсети. Маска подсети – это 4-байтовое число специального вида, которое используется совместно с IP-адресом. "Специальный вид" маски подсети заключается в следующем: двоичные разряды маски, соответствующие разрядам IP-адреса, отведенным под номер сети, содержат единицы, а в разрядах, соответствующих разрядам номера узла – нули. Использование в паре с IP -адресом маски подсети позволяет отказаться от применения классов адресов и сделать более гибкой всю систему IP-адресации. Так, например, маска 255.255.255.240 (11111111 11111111 11111111 11110000) позволяет разбить диапазон в 254 IP-адреса, относящихся к одной сети класса C, на 14 диапазонов, которые могут выделяться разным сетям.
Для более гибкого определения границ между разрядами номеров сети и узла внутри IP-адреса используются так называемые маски подсети. Маска подсети – это 4-байтовое число специального вида, которое используется совместно с IP-адресом. "Специальный вид" маски подсети заключается в следующем: двоичные разряды маски, соответствующие разрядам IP-адреса, отведенным под номер сети, содержат единицы, а в разрядах, соответствующих разрядам номера узла – нули. Использование в паре с IP -адресом маски подсети позволяет отказаться от применения классов адресов и сделать более гибкой всю систему IP-адресации. Так, например, маска 255.255.255.240 (11111111 11111111 11111111 11110000) позволяет разбить диапазон в 254 IP-адреса, относящихся к одной сети класса C, на 14 диапазонов, которые могут выделяться разным сетям.
56. Режимы адресации памяти микропроцессоров.
Регистровый и прямой режимы адресации. Привести примеры.
Режимы адресации памяти микропроцессоров.
1)
Прямой режим
адресации памяти МП.
2)
Режим регистровой
адресации памяти МП.
3)
Косвенная
адресация памяти МП.
4)
Косвенная
адресация со смещением.
5)
Базово-индексная
адресация памяти.
6)
Адресация строк
данных.
Регистровый режим адресации.
Команды
содержащие только регистровые операнды являются наиболее компактными, и
выполняются быстрее всех остальных типов команд.
Сегментные
регистры могут использоваться только как источники операндов.
Примеры:
1) INC CX; CX=CX+1
2)
Push DS; запись DS в сегмент стека.
3)
XCHG BX,BP; регистры BX и BP обмениваются
содержимым.
4)
Sub AX,BX; разность
двух операндов BX и AX, результат в AX.
Непосредственные операнды –
это пост-ые данные определённые как часть машинной команды. Данные операнды
могут быть 8 и 16 битовыми непосредственные операнды выбираются быстро т.к. МП
получает их прямо из очереди команд без обращения к памяти.
Непосредственные операнды
могут использоваться только как операнды источники.
Примеры:
1)
MOV AH,40h; число 40h загружается в AH.
2)
MOV AL,’*’; код символа * загружается в AL
3)
Int 21h; команда вызова процедуры обслуживания прерывания
21го типа (ОС).
4)
Limit
equ 528; число 528 получает обозначение Limit.
5)
CMP AL,02h; сравнение
содержимого регистра AL
Прямая адресация.
Простейшим видом адресации
является прямая т.к. она не использует ни каких регистров, адрес берётся
непосредственно из поля смещения машинной команды.
Физический адрес вычисляется
следующим образом:
Примеры:
1)
MOV AX,GAMMA; загрузить
в AX GAMMA.
2)
ADD TEMP, BL; прибавить BL к
переменной TEMP.
3)
MOV AX,TABLE; загружает
содержимое ячейки памяти TABLE
в регистр AX.
МП заполняет данные в памяти
в обратном порядке т.е. старший байт слова следует за младшим.
При такой адресации в
качестве исполнительно адреса выступает содержимое базового или индексного
регистров.
Комментариев нет:
Отправить комментарий